Artikel ini adalah overview sebuah Proof of Concept (PoC) yang sengaja dirancang untuk menjawab pertanyaan praktis:
Kalau beban naik, lebih baik memperbesar satu server (vertical scaling) atau menambah beberapa server kecil di belakang load balancer (horizontal scaling)?
Poin utamanya: load balancing bukan obat universal. Hasilnya sangat ditentukan oleh karakter workload—apakah bottleneck utamanya CPU, memory, atau hal lain.
Intuisi Dasar
Cara paling mudah membayangkan load balancer: ia berdiri di depan aplikasi, menerima request dari client, lalu memilih worker mana yang mengerjakan request tersebut.
Dalam skenario ideal, ini membantu:
- throughput naik (lebih banyak request selesai per detik),
- latency turun saat trafik mendadak naik, dan
- availability lebih baik (kalau satu worker bermasalah, masih ada yang lain).
Tapi di situ juga ada “syarat tersembunyi”: beban kerja harus bisa dipisah-pisah. Maksudnya, satu request bisa diselesaikan oleh satu worker tanpa perlu state bersama, dan bottleneck-nya memang ada di CPU / jumlah concurrency, bukan di kebutuhan memori minimum per request.
Desain Eksperimen
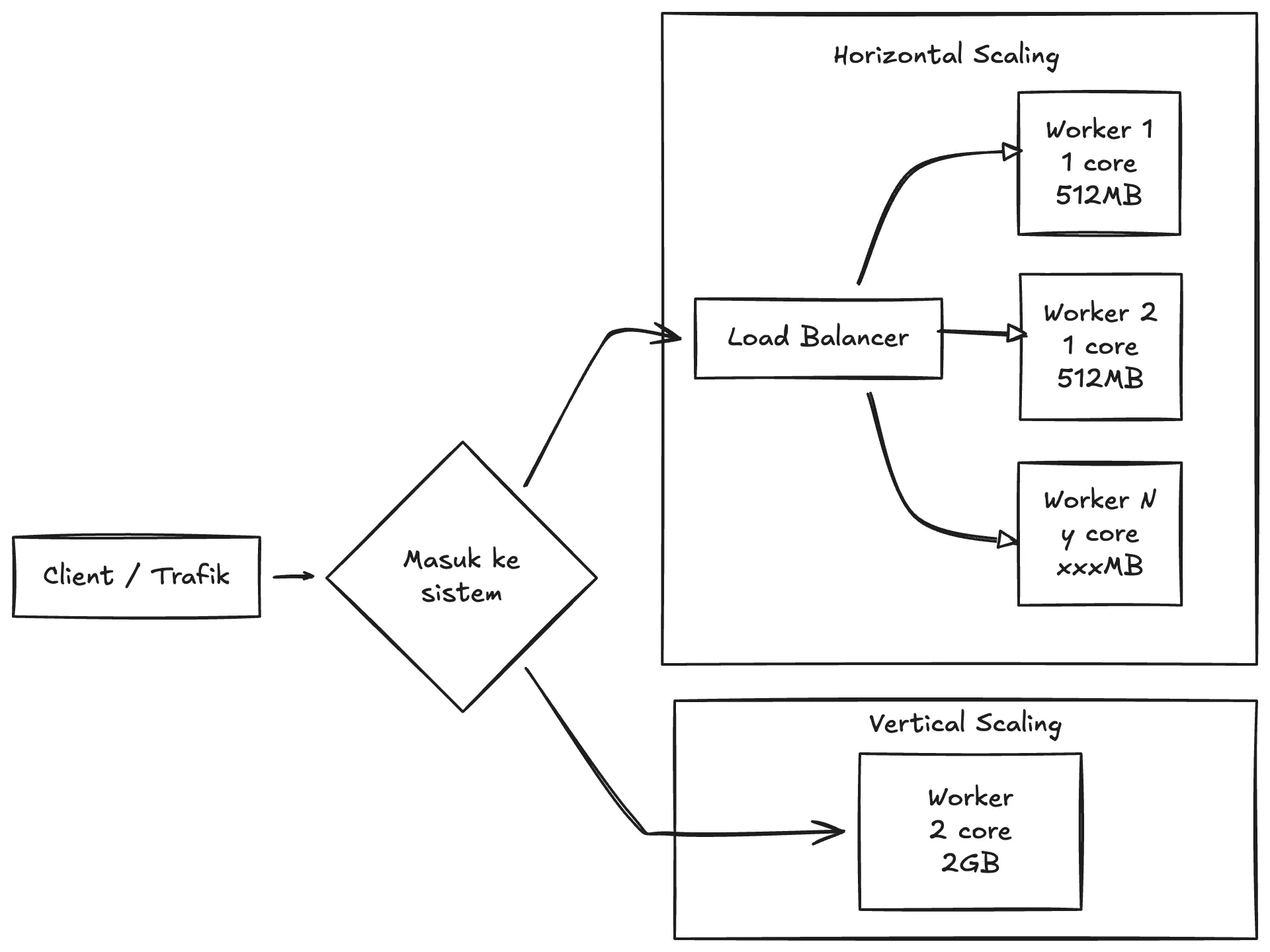
PoC ini membandingkan dua pendekatan scaling dengan total resource yang “kurang lebih sebanding”, tetapi distribusinya berbeda:
1) Vertical scaling: satu instance “lebih besar”
- Satu instance aplikasi dengan resource lebih lega.
- Semua request masuk ke instance yang sama.
2) Horizontal scaling: beberapa instance “lebih kecil” + load balancer
- Ada load balancer di depan.
- Request tersebar ke beberapa worker identik.
- Setiap worker punya resource lebih kecil per instance.
Catatan yang sering jadi sumber miskonsepsi: pada pola load balancing yang umum, satu request tetap dikerjakan oleh satu worker. Karena itu, horizontal scaling tidak otomatis menggabungkan RAM untuk membuat satu request “punya memori lebih besar”. Yang dibagi adalah jumlah request dan concurrency, bukan memori untuk satu request.
Dua Tipe Workload yang Sengaja Dibuat Kontras
Supaya beda hasilnya terasa jelas, PoC ini menyiapkan dua jenis workload yang sengaja dibuat kontras.
A) Workload CPU-bound dan stateless
Karakteristiknya:
- komputasi berat (misalnya agregasi, sorting, perhitungan statistik),
- state tidak perlu disimpan antar request,
- memory per request relatif kecil.
B) Workload memory-bound dan memory-intensive
Karakteristiknya:
- satu request perlu memuat/memproses dataset besar atau membuat “working set” besar,
- penggunaan memori tinggi dan sensitif terhadap batas RAM,
- ketika RAM tidak cukup, gejalanya bisa berupa OOM (proses mati), timeout, atau latensi yang sangat buruk karena thrashing.
Hasil Eksperimen
Hasil pengujian yang didapatkan saat mencoba PoC ini. Tujuannya bukan “menang siapa”, tapi melihat apakah pola yang muncul selaras dengan hipotesis di atas. Metrik-metrik yang digunakan sebagai patokan hasil adalah berikut:
- Throughput (mis. request per detik): apakah naik saat worker ditambah?
- Latency (terutama p95/p99): apakah tail latency membaik atau justru memburuk?
- Error rate: apakah ada timeout/5xx saat beban tinggi?
- Stabilitas: apakah proses sering restart (indikasi OOM) atau performa “naik-turun”?
1) Workload CPU-bound (stateless)
Pada workload yang dominan CPU dan relatif ringan di memori, konfigurasi horizontal (load balancer + beberapa worker) terlihat lebih unggul: request bisa dibagi, concurrency naik, dan tail latency turun.
| Konfigurasi | Total request | Success rate | Avg | p95 |
|---|---|---|---|---|
| Vertical (1 instance lebih besar) | 341 | 98.83% | 4217 ms | 17662 ms |
| Horizontal (LB + beberapa worker kecil) | 761 | 100% | 1369 ms | 2894 ms |
Interpretasi singkat:
- Total request yang selesai lebih banyak di mode horizontal (indikasi throughput lebih tinggi untuk beban jenis ini).
- p95 jauh lebih rendah di mode horizontal, yang biasanya berarti antrean/concurrency lebih “kebagi” antar worker.
2) Workload memory-bound (memory-intensive)
Di workload yang butuh memori besar per request, pola yang muncul kebalikannya: konfigurasi horizontal dengan worker kecil menjadi tidak stabil karena banyak request gagal.
| Konfigurasi | Total request | Success rate | Failed | Avg | p95 |
|---|---|---|---|---|---|
| Vertical (1 instance lebih besar) | 17 | 94.12% | 1 | 5138 ms | 6557 ms |
| Horizontal (LB + beberapa worker kecil) | 66 | 9.09% | 60 | 370 ms | 3788 ms |
Interpretasi singkat:
- Success rate yang jatuh tajam di mode horizontal adalah sinyal kuat bahwa kebutuhan RAM minimum per request tidak terpenuhi pada worker yang kecil.
- Angka rata-rata waktu respon pada mode yang banyak gagal bisa terlihat “bagus” secara semu (karena banyak request gagal lebih cepat), jadi metrik kuncinya di sini adalah error rate dan stabilitas.
Mengapa Load Balancing Bisa Menang (dan Mengapa Bisa Kalah)
Kapan load balancing unggul
- request stateless dan bisa diproses independen,
- bottleneck utama adalah CPU/concurrency,
- work per request cukup konsisten atau load balancer memakai strategi yang adaptif.
Contoh strategi distribusi yang sering dipakai:
- least connections: memilih worker dengan koneksi aktif paling sedikit; biasanya lebih adil saat durasi request bervariasi.
Kapan load balancing merugikan
- bottleneck utama adalah RAM per request,
- tiap worker “kecil” tidak memenuhi kebutuhan minimum untuk menyelesaikan request,
- overhead tambahan (hop ke load balancer, koneksi ekstra, cold cache per worker) memperparah tail latency.
Kalau gejala utamanya adalah OOM/timeout karena memory, menambah worker kecil sering tidak menyelesaikan akar masalah. Biasanya yang dibutuhkan justru lebih banyak RAM per instance (atau mengubah desain pemrosesan data supaya tidak memegang working set besar di memori).
Pelajaran Utama
- Load balancing itu strategi distribusi request, bukan jaminan performa.
- Horizontal scaling paling terasa manfaatnya untuk beban yang bisa diparalelkan (stateless, CPU-bound).
- Vertical scaling sering lebih aman saat bottleneck utamanya adalah RAM per request.
Kesimpulannya sederhana: sebelum memutuskan strategi scaling, cari dulu bottleneck dominan (CPU vs memory vs I/O). Setelah itu, pilih strategi yang benar-benar “menembak” bottleneck tersebut—bukan sekadar menambah komponen.