Dalam dunia microservices dan distributed systems, observability bukan lagi sekadar nice-to-have, melainkan kebutuhan mendasar. Ketika aplikasi tersebar di berbagai service, memahami apa yang terjadi di dalam sistem menjadi tantangan tersendiri.
Artikel ini membahas bagaimana membangun sistem observability lengkap menggunakan stack open source yang powerful. Kita akan membangun sebuah aplikasi order processing yang dilengkapi dengan tiga pilar observability: Logs, Metrics, dan Traces.
Arsitektur Sistem
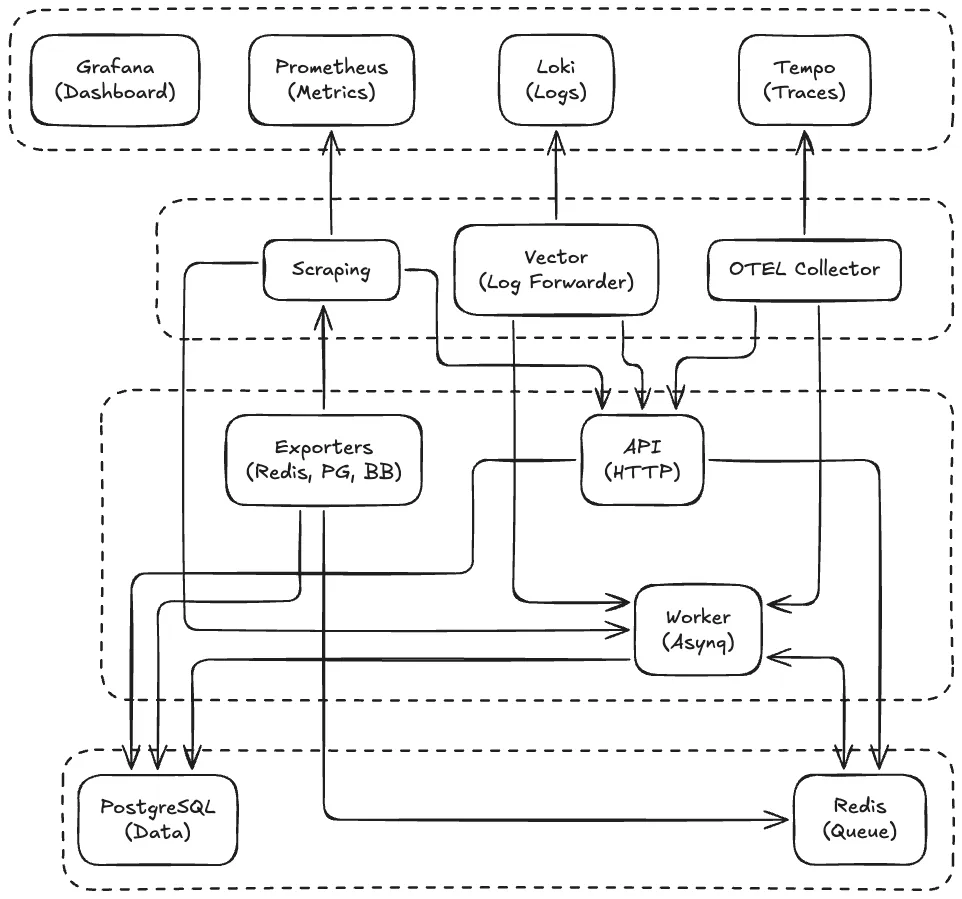
Stack Teknologi
Application Layer
| Komponen | Teknologi | Fungsi |
|---|---|---|
| Backend | Go (Golang) | Bahasa utama untuk API dan Worker |
| HTTP Router | Chi | Lightweight router untuk REST API |
| Task Queue | Asynq | Background job processing berbasis Redis |
| Database | PostgreSQL | Persistent storage untuk orders |
| Cache/Queue | Redis | Message broker untuk async jobs |
Observability Stack
| Komponen | Teknologi | Fungsi |
|---|---|---|
| Metrics | Prometheus | Time-series database untuk metrics |
| Logs | Loki | Log aggregation system |
| Traces | Tempo | Distributed tracing backend |
| Dashboard | Grafana | Unified visualization |
| Collector | OpenTelemetry | Telemetry data gateway |
| Log Forwarder | Vector | High-performance log shipper |
Konsep Tiga Pilar Observability
1. Logging — “Apa yang terjadi?”
Logs adalah rekaman detail dari event-event di sistem. Di proyek ini, kita menggunakan pendekatan structured logging dengan format JSON.
Konsep Implementasi:

Kenapa Structured Logging?
- Mudah di-parse dan di-query
- Konsisten antar service
- Mendukung correlation dengan trace ID
- Cocok untuk log aggregation system seperti Loki
Contoh Output Log:
{
"time": "2024-01-15T10:30:00Z",
"level": "INFO",
"msg": "order created",
"service": "api",
"order_id": "ord-123",
"customer_id": "cust-456",
"trace_id": "abc123..."
}
Flow:
- Aplikasi menulis log ke
stdoutdalam format JSON - Vector mendengarkan Docker socket dan mengumpulkan log dari semua container
- Log dikirim ke Loki untuk penyimpanan dan indexing
- Grafana digunakan untuk query dan visualisasi log
2. Metrics — “Seberapa sehat sistem?”
Metrics adalah data numerik yang menggambarkan state sistem dari waktu ke waktu. Kita menggunakan model pull-based dengan Prometheus.
Tipe Metrics yang Digunakan:
| Tipe | Contoh | Kegunaan |
|---|---|---|
| Counter | http_requests_total | Menghitung event kumulatif |
| Histogram | http_request_duration_seconds | Distribusi latency |
| Gauge | active_connections | Nilai yang naik-turun |
Custom Metrics:
orders_created_total— Total order yang dibuatworker_jobs_processed_total— Total job yang diproses workerworker_job_duration_seconds— Durasi processing job
Exporters untuk Infrastructure:
- Redis Exporter — Memory usage, connected clients, ops/sec
- Postgres Exporter — Connection pool, query stats, replication lag
- cAdvisor — Container resource usage (CPU, memory, network)
- Blackbox Exporter — Endpoint availability (HTTP probes)
3. Tracing — “Bagaimana request mengalir?”
Distributed tracing memungkinkan kita melacak perjalanan sebuah request melintasi berbagai service.
Konsep Implementasi:

Komponen Tracing:
- Trace — Keseluruhan perjalanan request
- Span — Satu unit kerja dalam trace
- Context Propagation — Meneruskan trace context antar service
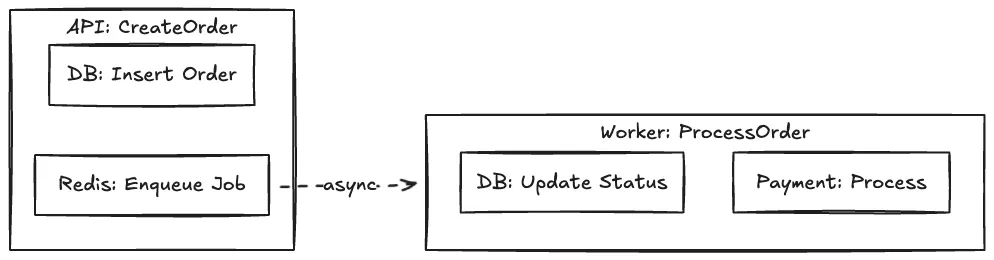
Contoh Trace Flow:
Sampling Strategy: Tidak semua trace perlu disimpan. Kita menggunakan Parent-Based Sampling dengan ratio 20%:
- 20% random trace disimpan lengkap
- Trace dengan error selalu disimpan
- Child span mengikuti keputusan parent
OpenTelemetry Collector — Central Gateway
OTEL Collector berperan sebagai gateway terpusat untuk semua telemetry data.
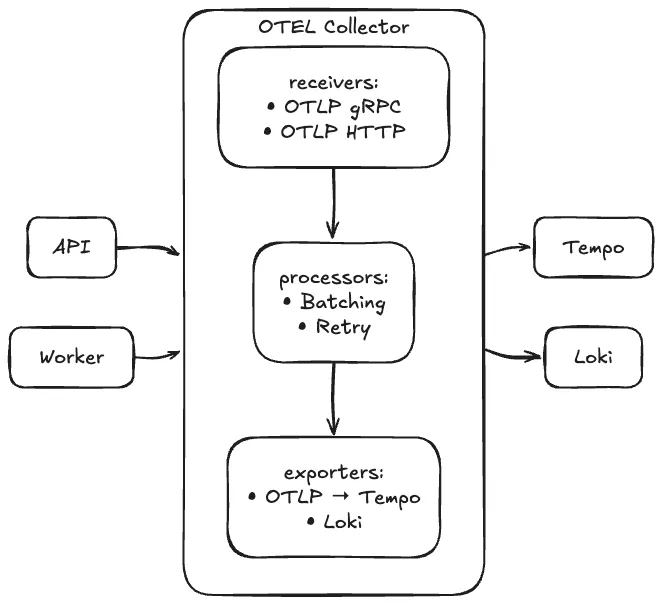
Keuntungan menggunakan Collector:
- Decoupling — Aplikasi tidak perlu tahu backend mana yang digunakan
- Batching — Mengurangi network overhead
- Retry — Automatic retry jika backend tidak available
- Multi-backend — Bisa export ke multiple destinations
- Protocol Translation — Convert antar format telemetry
Message Queue Pattern dengan Asynq
Untuk operasi yang membutuhkan waktu lama (seperti payment processing), kita menggunakan pattern async job queue.

Flow Order Processing:
- API menerima request
POST /v1/orders - Order disimpan ke PostgreSQL dengan status
pending - Job di-enqueue ke Redis
- API langsung response (tidak menunggu processing)
- Worker consume job dari Redis
- Worker process payment dan update status order
Keuntungan Pattern ini:
- Fast Response — User tidak menunggu processing selesai
- Reliability — Job tersimpan di Redis, tidak hilang jika worker crash
- Scalability — Bisa scale worker secara independen
- Retry — Built-in retry mechanism untuk failed jobs
Grafana — Unified Dashboard
Grafana menjadi single pane of glass untuk semua observability data.
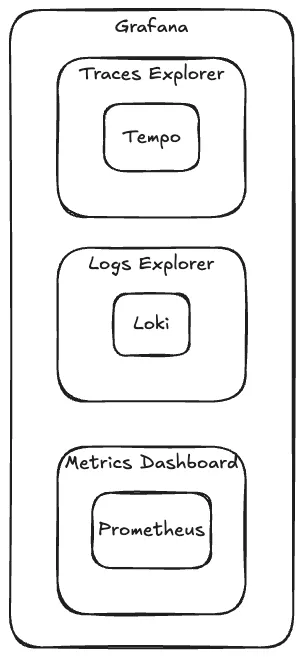
Fitur Penting:
- Datasource Integration — Native support untuk Prometheus, Loki, Tempo
- Explore — Ad-hoc query untuk debugging
- Exemplars — Link dari metrics ke traces
- Log → Trace — Click trace ID di log untuk melihat trace
- Unified Alerting — Alert dari metrics maupun logs
Kesimpulan
Membangun sistem observability yang komprehensif memang membutuhkan effort, tapi hasilnya sangat berharga:
- ✅ Faster Debugging — Dari metrics alert → log → trace dalam hitungan klik
- ✅ Proactive Monitoring — Deteksi masalah sebelum user complain
- ✅ Data-Driven Decisions — Metrics untuk capacity planning
- ✅ Reliable Systems — Understand failure modes melalui tracing
Stack open source seperti Grafana, Prometheus, Loki, dan Tempo memberikan capability yang setara dengan solusi commercial—dengan fleksibilitas dan cost yang lebih rendah.